

Data Strategy for Financial Services: From 50 Data Sources to an AI-Ready Lakehouse Platform

50 Data Sources and No Answers
A mid-sized financial services provider with over 2,000 employees and clients across the entire DACH region faced a paradox: the company possessed more data than ever before. Yet it couldn't answer a single simple question. How many customers use more than one product? Which datasets may be used for AI models? How current are the figures in regulatory reporting?
The data landscape had grown organically over years. Twelve departments worked with eight different database systems, supplemented by hundreds of Excel files and shadow IT solutions. Each department had its own version of the truth. None matched the others.
Initial AI initiatives had already failed. Not because of the technology, but because of the data foundation. A customer churn model produced unusable results because the training data came from three sources that used different customer definitions. The compliance department couldn't demonstrate which personal data was stored where. And any analysis beyond standard reports required an IT ticket with a three-week turnaround.
The realization: without a comprehensive data strategy, every further investment in AI, automation, or analytics would come to nothing.
Heading
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
From Data Silos to a Data Ecosystem. In Six Months.
Assessing data maturity
The starting point was not a technology decision but a data maturity assessment across all twelve departments. PLAN D inventoried all data sources, evaluated their quality, and analyzed actual usage patterns. The result was sobering and illuminating in equal measure: 73 percent of existing data was unusable for analytical or AI purposes. Not due to missing technology, but due to lacking quality, structure, and documentation. This assessment made the invisible visible and laid the foundation for every subsequent decision.
Designing the target architecture
Based on the assessment, PLAN D developed a domain-oriented target architecture together with the IT leadership, following data mesh principles. Instead of forcing all data into a central data warehouse, each business department received responsibility for its own data products. With clear interfaces, defined quality standards, and a unified access layer. The technology choice fell on the Databricks Lakehouse Platform: it combines the flexibility of a data lake with the structure of a data warehouse on a single system. The Delta Lake table format ensures transactional integrity and versioning. The Unity Catalog provides the central governance layer for metadata, access control, and data lineage.
Building data governance
A data architecture without governance is a building without structural integrity. PLAN D established a data governance framework that didn't end up as a document in a drawer but was integrated as lived practice into daily operations. Data stewards were appointed in every business department: employees who take responsibility for the quality, timeliness, and completeness of their data domain. Complemented by data owners at the management level and data engineers in IT, a continuous chain of accountability was created. The Unity Catalog became the single point of truth for all metadata: who created which data? Where does it come from? Who may use it? Every data source received documented lineage, from creation to its use in reports and models.
Implementing the data platform
In the implementation phase, the Databricks Lakehouse Platform went into production. Automated data pipelines took over the integration of 50+ data sources: ETL processes for batch data, change data capture for real-time streams from core banking systems. The Unity Catalog ensured that every transformation remained traceable. On top of this, a self-service BI layer was built, enabling business departments to create analyses independently. No IT ticket, no waiting time.
Enabling the organization
Technology alone doesn't transform an organization. PLAN D accompanied the rollout with a data literacy program that included all hierarchy levels. Data stewards received structured training in data quality management and governance processes. Business departments learned to use the self-service BI layer for their own analyses. And the executive board received an AI readiness assessment that prioritized concrete use cases based on the now cleansed data landscape. The starting signal for the next phase.
Understand Data. Use Data. Govern Data.
In six months, a fragmented data landscape was transformed into a comprehensive data ecosystem. All 50+ data sources are accessible via the Lakehouse platform, documented in the data catalog, and fully traceable through lineage. Data stewards in all twelve departments manage the quality of their data domains. Business departments create analyses independently. In minutes instead of weeks.
The result is more than a platform: it is the foundation for every future AI initiative, for reliable regulatory reporting, and for an organization that, for the first time, has a shared understanding of what data it owns and what it can do with it.
Zahlen & Fakten
6 Months
50+
73%
< 5 Min
So haben wir es umgesetzt
Data Lakehouse
Data Mesh
Data Pipelines
Data Catalog & Lineage
Data Governance
Self-Service BI
FAQs
A data strategy defines how a company collects, stores, manages, and uses its data to systematically derive value from it. It encompasses technical architecture, organizational responsibilities, and a concrete implementation plan.
Companies need a data strategy as soon as data is no longer only used within individual departments but becomes relevant across the organization. Without a strategy, data silos emerge, reports contradict each other, and AI projects fail due to poor data quality. In the financial sector, regulatory pressure adds another dimension: BaFin, GDPR, and the EU AI Act demand traceable data flows and documented data quality.
A data lakehouse combines the strengths of both architectures: the flexibility of a data lake for unstructured data with the structure and transactional integrity of a data warehouse for analytical queries. Technically, this is enabled by open table formats like Delta Lake, which provide ACID transactions directly on the data lake.
The advantage: instead of operating two separate systems and copying data between them, all use cases run on a single platform — real-time analytics, regulatory reporting, machine learning. This reduces complexity, costs, and the risk of inconsistent data.
Data governance encompasses the organizational rules, roles, and processes that ensure data is managed correctly, completely, traceably, and securely. The three central roles are data owner (strategic responsibility), data steward (operational data quality), and data engineer (technical implementation).
In the financial sector, data governance is not a nice-to-have but a regulatory obligation. Supervisory authorities expect traceable data flows, documented data provenance, and verifiable data quality at all times. Without lived governance, financial services providers risk not only erroneous reports but also regulatory consequences.
The timeframe depends on company size and the complexity of the data landscape. In this project, we achieved the full path from data maturity assessment to a productive Lakehouse platform in six months.
The decisive factor for speed is not technology but the organization's willingness to take responsibility for data. Companies that appoint data stewards early and provide management support for the project progress significantly faster.
Data mesh is an organizational principle where responsibility for data lies not centrally with IT but with the business departments that create and best understand the data. Each department is responsible for its data products — with defined quality standards, clear interfaces, and a shared infrastructure platform.
For mid-sized companies, data mesh becomes relevant when the organization is large enough that central data teams become a bottleneck. From around ten business departments and a double-digit number of data sources, decentralized responsibility solves a real problem. Important: data mesh does not mean anarchy. The technical platform and governance standards remain centralized.
Data quality is measured along defined dimensions: completeness (are values missing?), correctness (are the values accurate?), timeliness (how old is the data?), consistency (do sources contradict each other?), and uniqueness (are there duplicates?).
In practice, these dimensions are monitored through automated quality checks in the data pipelines. Every dataset undergoes validation during ingestion. The data catalog documents quality metrics for each data source. Data stewards regularly review the results and escalate deviations. This creates a continuous quality process rather than one-off cleansing campaigns.
AI models are only as good as their training data. A data strategy creates the prerequisites that AI projects need: clean, documented, accessible data in a unified format. Without this foundation, models fail due to contradictory customer definitions, missing values, or data that may not be used at all.
Specifically, an implemented data strategy delivers three things: first, a platform where data is available for training and inference. Second, governance that clarifies which data may be used for which purposes. Third, a data catalog that lets data scientists find data without having to ask each department individually. In this project, 73 percent of data was AI-ready for the first time after implementation. The foundation for the next projects.
Data stewards are the operational guardians of data quality in their business departments. They ensure that the data in their domain is correct, complete, and current. They define quality rules, monitor compliance, and are the first point of contact for data quality issues.
Unlike data owners (strategic responsibility, typically at management level) and data engineers (technical implementation, IT), data stewards work directly within the business unit. They understand the business logic behind the data and can assess whether a value is not only technically valid but also factually correct. In this project, data stewards were appointed in all twelve departments and trained in a structured program.
Mehr KI-Projekte aus der Praxis
700 Members, One AI
700+

Digital Strategy for 1.2 Million Members
100%

360° Customer View for Sales
2x
From AI Hesitation to an AI Roadmap
2

Price Prediction in Seconds
24h → 1 Sec.
Repair Costs in Seconds
93%
Data Strategy Instead of Data Silos
6 Months
50 Million Euros Through Data
~50 Mio. €


Expert Knowledge at the Touch of a Button
100


A Digital Future for the Energy Transition
7

AI Calculates Hail Damage
40.000+
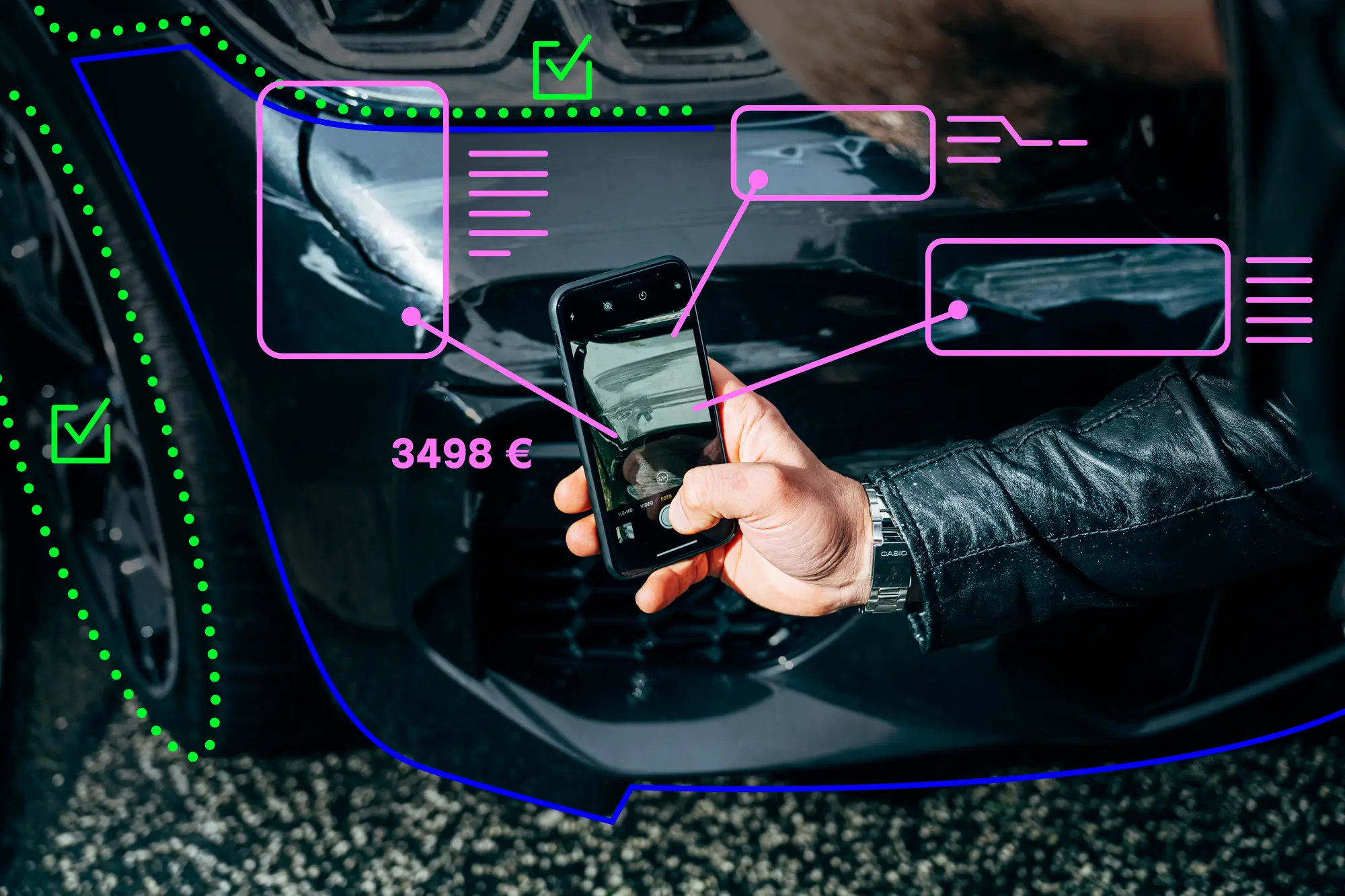
Computer Vision in Claims Management
93 %


Mit Daten Leben retten
1,3 Stunden


Remote Videobesichtigung von Kfz Schäden
100.000 Euro

Omnikanal im Versicherungsvertrieb
























Bereit wenn Sie es sind
Zukunft beginnt, wenn menschliche Intelligenz künstliche Intelligenz entwickelt. Der erste Schritt ist nur ein Klick.
Zukunft beginnt, wenn menschliche Intelligenz künstliche Intelligenz entwickelt. Der erste Schritt ist nur ein Klick.

KI Beratung
KI Entwicklung
KI Operations
Formate
Unternehmen
Rechtlichtes



