

Von 10 Jahren Transaktionsdaten zur verbindlichen Preisprognose in Echtzeit

Wenn Wertermittlung den Prozess bremst
In vielen Branchen ist die Wertermittlung ein Flaschenhals. Ob Gebrauchtmaschinen, Immobilien, IT-Assets oder Versicherungsfälle: Bevor ein Prozess weitergehen kann, muss ein Wert bestimmt werden. Und diese Bestimmung dauert. Stunden. Tage. Manchmal Wochen. Weil sie auf menschlicher Einschätzung basiert, auf Angebot und Nachfrage oder auf manueller Recherche.
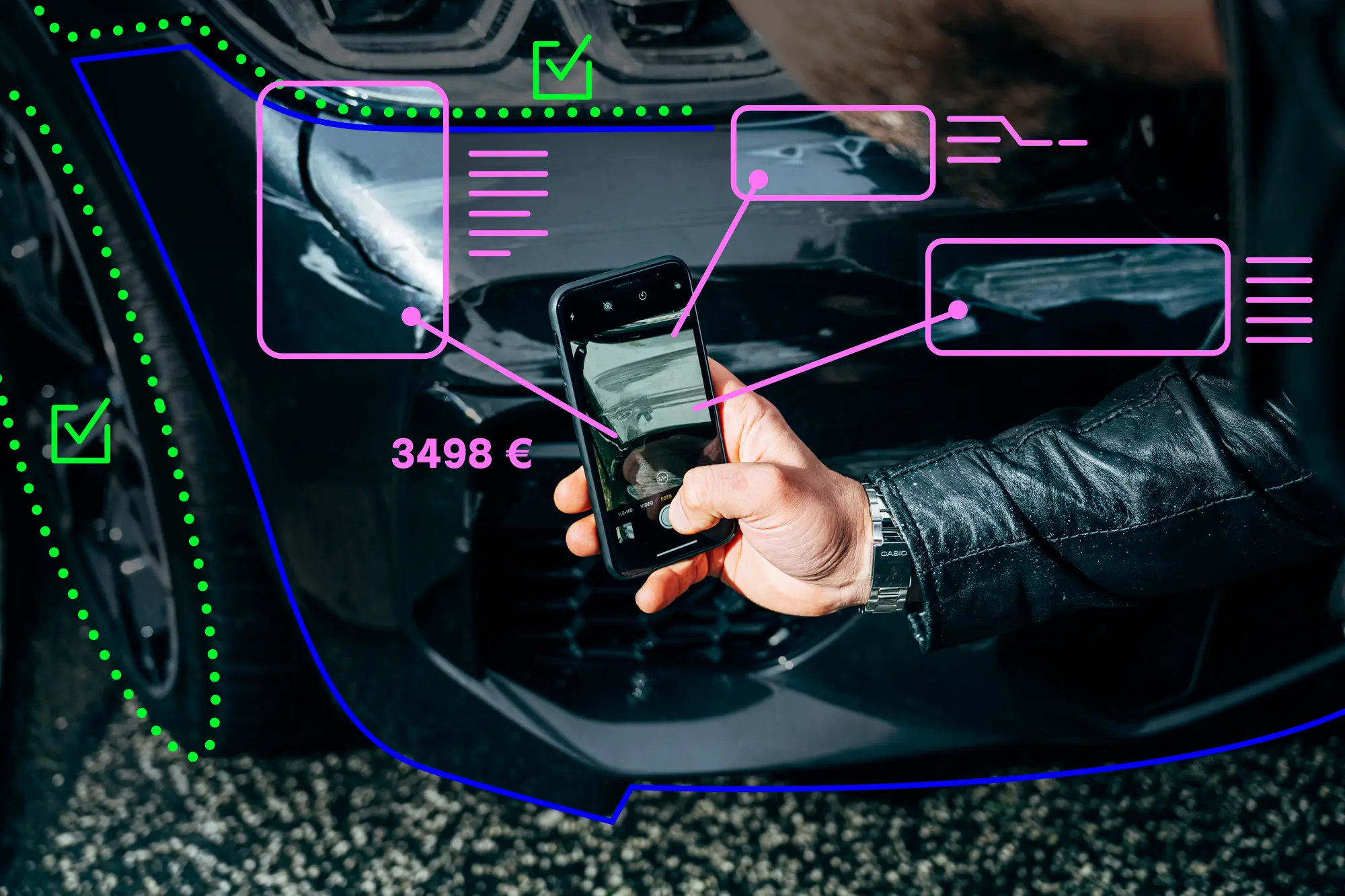
CarTV betreibt einen der größten europäischen Marktplätze für die Bewertung beschädigter Fahrzeuge. Täglich durchlaufen tausende Aufträge die Plattform. 10 Jahre an Transaktionsdaten liegen vor: Angebotspreise, realisierte Preise, Objektmerkmale, Käuferverhalten. Und trotzdem dauerte jede einzelne Wertermittlung mindestens 24 Stunden. Denn der Preis entstand nach dem klassischen Prinzip: Händler mussten erst bieten.
Bei Großereignissen wie Hagelschäden oder Überschwemmungen kommen tausende Fälle gleichzeitig. 24 Stunden pro Fall sind dann nicht akzeptabel. Gleichzeitig wächst der Druck durch Wettbewerber, die mit approximativen Schätzungen experimentieren. Ihr Problem: Eine Schätzung ist kein Preis. Und eine Prognose ohne Verbindlichkeit ist kein Differenzierungsmerkmal.
CarTV beauftragte PLAN D mit einer konkreten Aufgabenstellung: Eine KI-gestützte Preisprognose entwickeln, die so präzise ist, dass CarTV eine verbindliche Preisgarantie darauf aussprechen kann. Aus 24 Stunden sollen Sekunden werden. Und aus einer Prognose soll ein rechtlich belastbarer Wert werden.
Heading
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Vom Datenschatz zur Preisgarantie
Daten verstehen
Am Anfang stand nicht die Modellierung, sondern das Verständnis. 10 Jahre Transaktionsdaten, bei tausenden Aufträgen pro Tag: Angebotspreise, realisierte Verkaufspreise, Objektmerkmale, Schadensbilder, Marktdaten. Ein Datenschatz, der nie systematisch für Vorhersagen genutzt worden war.
PLAN D analysierte die Datenbestände, identifizierte Qualitätsprobleme und bereinigte die Datenbasis gemeinsam mit dem Fachteam von CarTV. Unplausible Werte, Ausreißer und inkonsistente Einträge wurden entfernt. Aus Rohdaten entstanden durch Feature Engineering aussagekräftige Merkmale: Kombinationen und Transformationen der Eingabevariablen, die dem Modell ermöglichen, Zusammenhänge zu erkennen, die in den Rohdaten nicht sichtbar sind.
Modell entwickeln
Auf Basis der bereinigten und aufbereiteten Daten testete PLAN D verschiedene Algorithmen. Die Wahl fiel auf ein Gradient-Boosting-Verfahren auf Basis von Entscheidungsbäumen (Decision Trees). Dabei werden Bäume sequenziell aufeinander aufgebaut. Jeder Baum korrigiert die Fehler des vorherigen. Das Ergebnis ist ein Modell, das schnell trainiert, effizient vorhersagt und interpretierbare Ergebnisse liefert.
Für zusätzliche Robustheit setzte PLAN D auf Ensemble Methods: Mehrere Modelle werden kombiniert, ihre Vorhersagen im Mehrheitsentscheid zusammengeführt. Statt einer Einzelmeinung entsteht eine abgesicherte Prognose, die weniger anfällig für Ausreißer und Overfitting ist.
Konfidenzintervall als Business-Hebel
Die eigentliche Innovation liegt nicht im Modell, sondern in seiner Anwendung. Das KI-System gibt nicht einen einzelnen Wert aus, sondern einen Preiskorridor: ein Konfidenzintervall, das angibt, in welchem Bereich der tatsächliche Preis mit hoher Wahrscheinlichkeit liegt. Auf dieser Basis lässt sich die Preisgarantie wirtschaftlich korrekt kalkulieren.
Das finanzielle Risiko ist kalkulierbar: Nicht alle Vorgänge führen tatsächlich zu einem Verkauf. Für diese Fälle tragen CarTV und die Versicherung das Differenzrisiko zwischen prognostiziertem und tatsächlich realisiertem Preis. So wird aus einer statistischen Vorhersage ein verbindliches Angebot, das rechtlich keinen Unterschied zu einem marktbasierten Preis macht.
Kein anderer Anbieter am Markt geht diesen Schritt. Wettbewerber liefern Prognosen, die als Orientierungswerte deklariert werden. CarTV liefert einen Preis. Mit Garantie.
Produktintegration
Das trainierte KI-Modell wurde als Docker-Container verpackt und nahtlos in die CarTV-Systeme integriert. Versicherungen und Gutachter rufen die Preisprognose über eine API-Schnittstelle ab. Ergänzend entstand eine Demonstrationsoberfläche für Kundenpräsentationen, mit der CarTV die Funktionsweise des Modells transparent erklären kann.
Die gesamte Architektur ist auf Unabhängigkeit ausgelegt: Das KI-Modell läuft in der hauseigenen IT-Infrastruktur von CarTV. Keine Cloud-Abhängigkeit im Produktivbetrieb.
Prognose wird Preis
CarTV verfügt über die erste und einzige KI-basierte Wertermittlung am Markt, die einen verbindlichen Preis ausgibt. Keine Schätzung, kein Orientierungswert, sondern eine Preisgarantie.
Das KI-Modell erreicht ein R² von über 90 Prozent: Über 90 Prozent der Varianz in den Preisdaten werden durch das Modell erklärt. Der mittlere absolute prozentuale Fehler (MAPE) liegt bei unter 10 Prozent. Die Prognose erfolgt in Sekunden statt in 24 Stunden.
Für Versicherungen und Gutachter bedeutet das: schnellere Fallbearbeitung, kürzere Durchlaufzeiten, zufriedenere Kunden. Für CarTV bedeutet es ein Alleinstellungsmerkmal, das kein Wettbewerber bietet, und ein Mehrerlöspotenzial im Millionenbereich.
Das Muster hinter diesem Ergebnis ist branchenübergreifend übertragbar. Überall dort, wo Unternehmen historische Transaktionsdaten besitzen und daraus verbindliche Preise ableiten wollen, lässt sich ein vergleichbarer Ansatz umsetzen: Gebrauchtmaschinen, Immobilien, IT-Assets, Rohstoffe. Das Prinzip ist identisch. Die Daten sind andere.
Zahlen & Fakten
24h → 1 Sek.
> 90 %
10 Jahre
< 10 %
So haben wir es umgesetzt
LightGBM
Ensemble Methods
Feature Engineering
Data Pipelines
Machine Learning
Containerization
Fragen & Antworten
Ein KI-Modell lernt aus historischen Transaktionsdaten die Zusammenhänge zwischen Objektmerkmalen und tatsächlich erzielten Preisen. Dazu gehören Eigenschaften wie Alter, Zustand, Marktsegment und historische Preisentwicklung. Das Modell erkennt Muster, die in der Masse der Daten verborgen sind, und leitet daraus eine Preisprognose für neue, noch nicht bewertete Objekte ab.
Entscheidend für die Qualität ist die Datengrundlage: Je mehr historische Transaktionen vorliegen und je konsistenter die Daten sind, desto präziser wird die Vorhersage. In diesem Projekt standen 10 Jahre Transaktionsdaten mit tausenden Aufträgen pro Tag zur Verfügung. Diese Breite und Tiefe ermöglichte ein Modell, das präzise genug für verbindliche Preiszusagen ist.
Ein Konfidenzintervall gibt an, in welchem Bereich der tatsächliche Preis mit einer definierten Wahrscheinlichkeit liegt. Statt eines einzelnen Werts liefert das Modell einen Korridor, zum Beispiel: „Der Preis liegt mit 90 Prozent Wahrscheinlichkeit zwischen 3.200 und 4.100 Euro.“
Der Vorteil gegenüber einem Punktwert: Unsicherheit wird sichtbar und steuerbar. Ein Unternehmen kann das Konfidenzintervall für Risikosteuerung nutzen, beispielsweise indem es eine Garantie für einen Wert am Rand des Intervalls ausspricht. Damit wird das finanzielle Risiko kalkulierbar, und aus einer statistischen Prognose entsteht ein verbindliches Geschäftsinstrument.
In den meisten Anwendungen bleibt eine KI-Prognose ein Orientierungswert: nützlich für Entscheidungen, aber ohne Bindungswirkung. Der Schritt zur Verbindlichkeit erfordert ein Modell, das präzise genug ist, und ein Geschäftsmodell, das das Restrisiko einkalkuliert. In Einzelfällen kann die Abweichung zwischen Prognose und tatsächlichem Preis zu einem schlechten Deal führen. In der Masse sind solche Ansätze aber wirtschaftlich sinnvoll, weil sich Über- und Unterschätzungen statistisch ausgleichen. So macht die Kombination aus präzisem Modell und kalkuliertem Risiko aus Predictive Analytics ein verbindliches Preismodell.
LightGBM ist ein Gradient-Boosting-Framework, das auf Entscheidungsbäumen basiert. Es erstellt sequenziell Bäume, wobei jeder neue Baum die Fehler des vorherigen korrigiert. Das Verfahren ist besonders geeignet für strukturierte, tabellarische Daten mit vielen Merkmalen.
Für Preisprognosen auf Transaktionsdaten ist LightGBM aus mehreren Gründen gut geeignet: Es verarbeitet große Datenmengen effizient, erfasst komplexe nichtlineare Zusammenhänge zwischen Merkmalen und liefert interpretierbare Ergebnisse. Im Vergleich zu neuronalen Netzen benötigt LightGBM weniger Trainingsdaten und Rechenressourcen und ist weniger anfällig für Overfitting bei strukturierten Daten.
Die Mindestanforderung sind historische Transaktionsdaten mit drei Komponenten: Objektmerkmale (was wurde bewertet?), Angebotspreise oder Schätzungen (was wurde erwartet?) und realisierte Preise (was wurde tatsächlich gezahlt?). Je nach Branche kommen Marktdaten, Zeitreihen und externe Datenquellen hinzu.
Die eigentliche Vorarbeit liegt in der Datenbereinigung und im Feature Engineering: Ausreißer entfernen, Inkonsistenzen auflösen, aus Rohdaten aussagekräftige Merkmale ableiten. In den meisten Unternehmen liegen die notwendigen Daten bereits vor. Was fehlt, ist nicht die Datenmenge, sondern die systematische Aufbereitung und Nutzung.
Die Güte eines Prognosemodells wird über statistische Metriken bewertet, die verschiedene Aspekte der Vorhersagequalität abbilden. Die wichtigsten Kennzahlen im Kontext von Predictive Analytics sind R², MAPE und MAE.
R² (Bestimmtheitsmaß) gibt an, welcher Anteil der Preisvariation durch das Modell erklärt wird. Ein R² von über 90 Prozent bedeutet: Das Modell erfasst über 90 Prozent der systematischen Preisunterschiede. MAPE (Mean Absolute Percentage Error) misst die durchschnittliche prozentuale Abweichung zwischen Prognose und tatsächlichem Preis. MAE (Mean Absolute Error) gibt die durchschnittliche absolute Abweichung in Euro an. Die Kombination dieser Metriken ergibt ein differenziertes Bild: R² misst die Erklärungskraft, MAPE die relative Treffsicherheit und MAE die wirtschaftliche Relevanz der Abweichung.
Das Grundprinzip ist branchenübergreifend anwendbar. Überall dort, wo historische Transaktionsdaten vorliegen und Preise auf Basis von Objektmerkmalen bestimmt werden, lässt sich ein vergleichbares Modell aufbauen: Gebrauchtmaschinen, Immobilien, IT-Assets, B2B-Restposten, Rohstoffe.
Die Voraussetzungen sind in jeder Branche dieselben: eine ausreichende Datenbasis historischer Transaktionen, strukturierte Objektmerkmale und ein definierter Bewertungsprozess. Was sich ändert, sind die Merkmale (Features), die Datenquellen und die branchenspezifischen Besonderheiten. Das statistische Verfahren und die Architektur bleiben identisch. Unternehmen im Mittelstand, die über mehrere Jahre Transaktionsdaten verfügen, haben damit die Grundlage für eine KI-gestützte Preisfindung.
Die Integration erfolgt über eine Containerisierung des trainierten Modells als Docker-Image. Der Container wird in der bestehenden IT-Infrastruktur des Kunden betrieben und über eine API-Schnittstelle angesprochen. Bestehende Systeme rufen die Prognose als Service ab, ohne ihre eigene Architektur ändern zu müssen.
In diesem Projekt wurde das KI-Modell in die CarTV-Systeme integriert. Versicherungen und Gutachter nutzen die Prognose über dieselbe Oberfläche, die sie bereits kennen. Der Vorteil der Container-Architektur: Das Modell kann unabhängig von der restlichen Anwendung aktualisiert, skaliert und überwacht werden. Es entsteht keine Cloud-Abhängigkeit im Produktivbetrieb.
Mehr KI-Projekte aus der Praxis

700 Mitglieder, eine KI
700+

Digitalstrategie für 1,2 Millionen Mitglieder
100%

360°-Kundensicht für den Vertrieb
2x

Von KI-Zurückhaltung zur KI Roadmap
2
Preisprognose in Sekunden
24h → 1 Sek.
Reparaturkosten in Sekunden
93 %
Datenstrategie statt Datensilos
6 Monate
50 Millionen Euro durch Daten
~50 Mio. €


Fachwissen auf Knopfdruck
100


Digitale Zukunft für die Energiewende
7

KI kalkuliert Hagelschäden
40.000+
Computer Vision im Schadenmanagement
93 %


Mit Daten Leben retten
1,3 Stunden


Remote Videobesichtigung von Kfz Schäden
100.000 Euro

Omnikanal im Versicherungsvertrieb
























Bereit wenn Sie es sind
Zukunft beginnt, wenn menschliche Intelligenz künstliche Intelligenz entwickelt. Der erste Schritt ist nur ein Klick.
Zukunft beginnt, wenn menschliche Intelligenz künstliche Intelligenz entwickelt. Der erste Schritt ist nur ein Klick.

KI Beratung
KI Entwicklung
KI Operations
Formate
Unternehmen
Rechtlichtes



